Notice:


People

Kaifeng Lyu
Machine Learning Theory, AI Safety/Alignment, Optimization
I am a postdoctoral research fellow at the Simons Institute at UC Berkeley. Before that, I obtained my Ph.D. in Computer Science in 2024 from Princeton University and I was very fortunate to be advised by Prof. Sanjeev Arora. I will be joining the Institute for Interdisciplinary Information Sciences (IIIS) at Tsinghua University as a Tenure-Track Assistant Professor in June 2025.
I did my undergraduate at Tsinghua University and received a B.Eng. in Computer Science and Technology in 2019. At Tsinghua, I was a student of Yao Class headed by Prof. Andrew Chi-Chih Yao and I was very fortunate to be advised by Prof. Jian Li.
 Research Interests
Research Interests
I am primarily interested in machine learning theory, AI safety/alignment, and optimization.
Recruitment for Ph.D. students
Please see the Chinese version of this page for more information.
会议论文
ICML 2025
Weak-to-Strong Generalization Even in Random Feature Networks, Provably
Marko Medvedev*,Kaifeng Lyu*,Dingli Yu,Sanjeev Arora,Zhiyuan Li,Nathan Srebro
A Multi-Power Law for Loss Curve Prediction Across Learning Rate Schedules
Kairong Luo,Haodong Wen,Shengding Hu,Zhenbo Sun,Zhiyuan Liu,Maosong Sun,Kaifeng Lyu,Wenguang Chen
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
Kaiyue Wen*,Xingyu Dang*,Kaifeng Lyu
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Xiangyu Qi,Ashwinee Panda,Kaifeng Lyu,Xiao Ma,Subhrajit Roy,Ahmad Beirami,Prateek Mittal,Peter Henderson
Oral Presentation (Top 1.8%). Outstanding Paper Award (Top 3/3827=0.08%).
Feature Averaging: An Implicit Bias of Gradient Descent Leading to Non-Robustness in Neural Networks
Binghui Li*,Zhixuan Pan*,Kaifeng Lyu,Jian Li
Efficient Stagewise Pretraining via Progressive Subnetworks
Abhishek Panigrahi*,Nikunj Saunshi*,Kaifeng Lyu,Sobhan Miryoosefi,Sashank Reddi,Satyen Kale,Sanjiv Kumar
Towards Understanding Text Hallucination of Diffusion Models via Local Generation Bias
Rui Lu*,Runzhe Wang*,Kaifeng Lyu,Xitai Jiang,Gao Huang,Mengdi Wang
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Kaifeng Lyu*,Haoyu Zhao*,Xinran Gu*,Dingli Yu,Anirudh Goyal,Sanjeev Arora
A Quadratic Synchronization Rule for Distributed Deep Learning
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
Kaifeng Lyu*,Jikai Jin*,Zhiyuan Li,Simon S. Du,Jason D. Lee,Wei Hu
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Yongchao Zhou,Kaifeng Lyu,Ankit Singh Rawat,Aditya Krishna Menon,Afshin Rostamizadeh,Sanjiv Kumar,Jean-François Kagy,Rishabh Agarwal
The Marginal Value of Momentum for Small Learning Rate SGD
Runzhe Wang,Sadhika Malladi,Tianhao Wang,Kaifeng Lyu,Zhiyuan Li
Understanding incremental learning of gradient descent: A fine-grained analysis of matrix sensing
Jikai Jin,Zhiyuan Li,Kaifeng Lyu,Simon S. Du,Jason D. Lee
Why (and When) does Local SGD Generalize Better than SGD?
Xinran Gu*,Kaifeng Lyu*,Longbo Huang,Sanjeev Arora
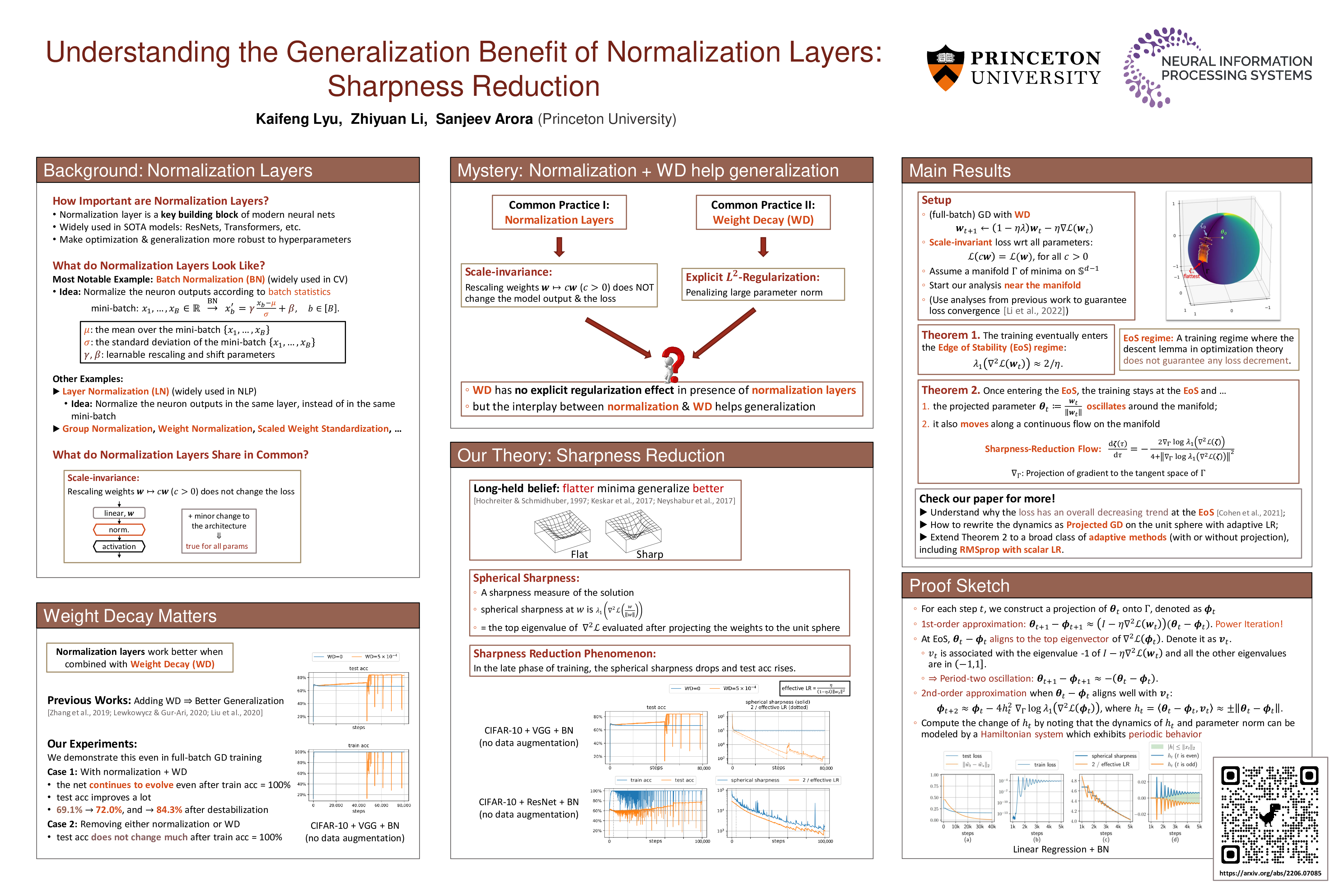
Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction
Kaifeng Lyu,Zhiyuan Li,Sanjeev Arora
On the SDEs and Scaling Rules for Adaptive Gradient Algorithms
Sadhika Malladi*,Kaifeng Lyu*,Abhishek Panigrahi,Sanjeev Arora
New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound
Arushi Gupta*,Nikunj Saunshi*,Dingli Yu*,Kaifeng Lyu,Sanjeev Arora
Oral Presentation (Top 1.9%).
Gradient Descent on Two-layer Nets: Margin Maximization and Simplicity Bias
Kaifeng Lyu*,Zhiyuan Li*,Runzhe Wang*,Sanjeev Arora
Towards Resolving the Implicit Bias of Gradient Descent for Matrix Factorization: Greedy Low-Rank Learning
Zhiyuan Li,Yuping Luo,Kaifeng Lyu
(按字母序排序)
Reconciling Modern Deep Learning with Traditional Optimization Analyses: The Intrinsic Learning Rate
Zhiyuan Li*,Kaifeng Lyu*,Sanjeev Arora
Gradient Descent Maximizes the Margin of Homogeneous Neural Networks
Kaifeng Lyu,Jian Li
Oral Presentation (Top 1.9%).
Theoretical Analysis of Auto Rate-Tuning by Batch Normalization
Sanjeev Arora,Zhiyuan Li,Kaifeng Lyu
(按字母序排序)
Fine-grained complexity meets IP = PSPACE
Lijie Chen,Shafi Goldwasser,Kaifeng Lyu,Guy N Rothblum,Aviad Rubinstein
(按字母序排序)
Single-Source Bottleneck Path Algorithm Faster than Sorting for Sparse Graphs
Ran Duan,Kaifeng Lyu,Hongxun Wu,Yuanhang Xie
(按字母序排序)
(Contribution order by default; Asterisk * stands for equal contribution.)
Students
PhD Students:
Haodong Wen (incoming)
Kexian Tang (incoming)
Master's Student:
Rui Chen (incoming)
Teaching
Planned Courses
Fall 2025. Large Language Models from Scratch: Theory and Practice, Tsinghua University.
Teaching Assistant Experience
Spring 2024. Teaching Assistant for COS324: Introduction to Machine Learning (by Prof. Sanjeev Arora & Prof. Elad Hazan), Princeton University.
Fall 2022. Teaching Assistant for COS521: Advanced Algorithm Design (by Prof. Matt Weinberg & Prof. Huacheng Yu), Princeton University.
Spring 2021. Teaching Assistant for COS598B: Advanced Topics in Computer Science: Mathematical Understanding of Deep Learning (by Prof. Sanjeev Arora), Princeton University.
Spring 2020. Teaching Assistant for Mathematics for Computer Science (by Prof. Andrew Chi-Chih Yao), Tsinghua University.
Spring 2019. Teaching Assistant for Distributed Computing (by Prof. Wei Chen), Tsinghua University.
Service
Professional Services
Organizer, NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning (M3L 2024).
Organizer, NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning (M3L 2023).
Conference Reviewer: ICML (2020-2025), NeurIPS (2020-2023), ICLR (2022-2025), TPAMI, COLT (2020,2025), AAAI (2020), KDD (2022).
Journal Reviewer: TMLR, JMLR, TPAMI, AIJ.
Organizer, Yao Class Seminar, Tsinghua University (Fall 2019, Fall 2020, Spring 2021).
Universal Online Judge
I founded the Universal Online Judge (UOJ) in 2014, a popular online judge system in China.
UOJ is capable of testing both traditional and non-traditional programming problems in OI (Olympiad in Informatics). A team of top OI players regularly hosts programming contests on UOJ.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}